三井住友カードのメール問合せページが検索エンジンでヒットしない仕組み
当サイトには広告を含みます。広告でなく単なる紹介等の場合もあります。
当サイトでは、広告掲載ポリシーに沿って広告を掲載しています。
※広告でなく、単に商品やサービスを自主的に紹介しているだけという場合もあります。
その中でも "オススメ" として紹介している商品やサービスは、個人的にそう思えたものだけです。
共感、興味をもっていただけるものがあればご利用ください。


三井住友カードへの問い合わせ方法には、電話やチャット以外に、Eメールで後日回答いただける問い合わせフォームもあるのですが、そのWebページ自体はGoogle等の検索エンジンでヒットしないようになっています (2023年11月時点)。
そのWebサイトの設計として、意図的にGoogle等の検索エンジンに登録されないようにしているためだと考えられます。
本記事では、(三井住友カードのサポートのフローが分かりづらいという愚痴ではなく) サポートサービスにおけるフローの現状や、また技術的なSEO (Search Engine Optimization) の観点から、そのメール問い合わせページを例に、特定のページ (というか今回はサイト) を検索エンジンに登録させないために、クローラによる探索を許可しないよう設定する方法を確認します。
※本記事には、その問い合わせフォームの具体的なURLについては記載していません。意図的に見つかりにくくしてあるものを、一般公開された媒体に掲載しないためです。また、Webページを対象とした内容ですので、モバイルデバイス上のアプリでの操作等については対象外です。
本記事の想定読者
- SEOにおいてWebサイトを検索エンジンに登録をさせない方法の一例を知りたい方
- 三井住友カードのメール問合せページが検索エンジンでヒットしない仕組みを純粋に知りたい方
※本記事の視点、文脈がやや散漫としているので、記載しました。
注意
本記事の内容は個人的な調査結果や経験に基づいたものです。
正確かどうか、最新かどうかについては、公式情報等をお確かめください。
三井住友カードのサポートに繋がりにくい問題
背景として記載しておきます。
人気のある三井住友カードですが、一方で問い合わせ窓口に繋がりにくいという不満の声もよく目にします (2023年11月時点)。
確かに繋がりにくい
それは確かにそのとおりだと思います。最近、電話窓口は繋がったためしがないです。
例えば、基本的にFAQと重複した内容の自動応答メニューばかりで、オペレーターに繋いでもらうために、どのメニューを選択すればよいかが分かりづらく、何回もかけ直すことがあるかもしれません。また、やっとオペレータに繋いでもらえるメニューを選択できたと思ったら、次は “混みあっていますので折り返します” と案内されますが、その後なんと、”予約枠に空きがありません” と通知されてしまい、折り返しの予約ができず、結局何の成果もないまま、通話終了になります (フリーダイヤルでない場合、電話代だけが無駄になります)。
私自身、いちユーザとして、サポートが必要なユーザに提示するフローの改善や、カードランクに応じたサポートサービスのランク分け等、三井住友カードに対して “意見” を挙げたりもしました。
サポートが必要なユーザにとって適切なフローになっていない
そのような状況なので、電話窓口 (やその前にFAQ、AIチャット等も経て) で解決できなかった人たちはサポート難民となり、つながる窓口を探し、さまよい続けます。
サポートが必要なユーザが次に取るべきアクションが明確に提示されていないという意味で、残念ながらフローが破綻している印象です。
最後の望みのメール問い合わせも見つからない
電話でなく、メール問い合わせであれば用件を送信してから回答を待てばよいのですが、その問い合わせフォームがあるWebページは、一般的な検索エンジンでは全くヒットしません (以前は確か検索エンジンでヒットしていたか、あるいはもう少したどり着きやすかった気がします)。
これは、後述の確認結果から、Webサイトとしての意図的な設計であると考えられます。
しかしただ見守るだけ
とりあえず今後の改善に期待しつつ、(我慢できる範囲内で) そっと見守りたいと思います。
特にできることはありません。
※無制限に受付可能なメール問い合わせ窓口が見つかりやすいことにより、サポート体制自体がパンクしてしまっては元も子もないので、サポートサービス全体としての改善を見守るのがベストだと、個人的には思います。
…と、背景はここまでです。
以降は、この背景のうち、メール問い合わせを行うためのWebページが検索エンジンで全くヒットしない点に着目し、その仕組みを確認していきます。
メール問い合わせページにたどり着くまでの遷移
Webブラウザにて、今回のメール問い合わせページにアクセスするまでの遷移は以下のとおりです。
- ページA: メール問い合わせとは直接関係の無いページ
↓ ページA内のリンク - ページB: メール問い合わせフォームとは別のページ ※
↓ ページB内のリンク - ページC: メール問い合わせフォームのページ (目的のページ) ※
(具体的なURLについては記載していません)
上記のように関係の無いページからリンクを複数たどる必要性があるので、メール問い合わせフォームを開きたい人が通常のWeb検索 (オーガニック検索) から自然にたどり着くことはできないようになっています。
※のページB、Cは通常の検索エンジンでヒットしないようになっています。ただし、ページAはメール問い合わせとは直接関係の無い別のキーワードで検索するとヒットはします。
本記事では、サイト全体としてのクローラ向けアクセス設定 (robots.txt) と、上記のページA~Cの実装について確認していきます。
検索エンジンに登録させないための仕組み
今回確認したメール問い合わせに関連するWebページおよびそのドメインでは、検索エンジンに登録させないための設定が行われています。
検索エンジンに登録させないための設定としては、robots.txtの設定だけで必要十分そうな気がしますが、補足情報として、各ページの実装についても記載します。
なお、検索エンジンの仕様を確認する際の例として、Googleのドキュメントをいくつか引用しています。他の検索エンジンについては調べていませんが、おそらく似たような実装になっているはずです。
サイト全体としてのクローラ向けアクセス設定 (robots.txt)
まず、サイト全体としてのクローラ向けアクセス設定を定義する robots.txt がどのように公開されているかについてです。
対象のWebページ (前述のページBとC) のドメインでは、クローラ向けアクセス設定 (robots.txt) にアクセスできないようになっています。
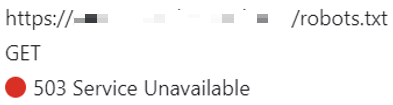
https://(対象ドメイン)/robots.txt にアクセスした際に表示される画面は以下です。

また、上記の画面を表示する際、Webサーバから受け取っているHTTPとしての応答ステータスコードは200番台 (Successful 2xx) でなく、500番台 (Server Error 5xx) の503 Service Unavailableです (Chrome 開発者ツールにて確認)。
ちなみに、本題から少しそれますが、上記の画面において、アクセスできない理由を説明するメッセージ内容が、”メンテナンスのため停止” や ”しばらく時間を置いてから” のように、恒久的 (permanent) なニュアンスでなく、一時的 (temporary、しかも数時間くらいで復旧しそう) なものとなっている点には、少し違和感があります。
robots.txtの500番台エラーは "クロールを許可しない"
robots.txtへのアクセスがHTTPの400番台でなく、500番台のエラーとなる場合、”クロールを許可しない” という意味になります。
検索エンジンのクローラ等が動作する際の REP (Robots Exclusion Protocol) を定義したRFC 9309では、HTTPの500番台エラーについて “the crawler MUST assume complete disallow” と記述されています。
この場合、RFCの文脈やGoogleの実装から察するに、”該当のドメイン全体に対してクローラによるアクセスを許可しない” という意味になると思われます。
つまり、REP に従う普通の検索エンジンのクローラであれば、robots.txtへのアクセスがHTTPの500番台エラーとなるドメインのWebサイト全体が、検索エンジンに登録されないということになります。
よって、三井住友カードのメール問合せページが検索エンジンでヒットしない理由は、この仕組みによるものであると考えられます。
RFC9309等の参考URL
以下は、上記の内容のもとになっている参考URLです。
- RFC 9309: Robots Exclusion Protocol の 2.3.1.4. “Unreachable” Status
- Google による robots.txt の指定の解釈 | Google 検索セントラル | ドキュメント | Google for Developers
- The Web Robots Pages
- LinkedInのGary Illyes: A robots.txt file that returns a 500/503 HTTP status code for an extended… | 40件のコメント
ちなみに、RFC9309は2022年9月の発行で、その著者のほとんどが Google LLC の所属です。
Googleの実装における500番台エラーの補足
Googleの説明ページを見ていると、RFC9309には書かれていないような細かな点も含め、独自の実装もあるようです。
robots.txtへのアクセスがHTTPの500番台エラーとなる場合の説明を以下に引用します。
5xx (server errors)
robots.txt リクエストに対してサーバーから明確な応答がないため、Google は一時的な 5xx および 429 のサーバーエラーと解釈し、サイトが完全に許可されていない場合と同様に処理します。Google は、サーバーエラー以外の HTTP ステータス コードを取得するまで robots.txt ファイルのクロールを試行します。503 (service unavailable) エラーの場合、再試行が頻繁に行われます。robots.txt に 30 日以上アクセスできない場合、Google は robots.txt の最後のキャッシュ コピーを使用します。使用できない場合、Google はクロールに対する制限はないと見なします。
クロールを一時的に停止する必要がある場合は、サイト上のすべての URL で 503 HTTP ステータス コードを返すことをおすすめします。
Google は、サイトが誤って構成されているためにページ不明の 404 ではなく 5xx が返されていると判断できる場合、そのサイトからの 5xx エラーを 404 エラーとして扱います。たとえば、5xx ステータス コードを返すページのエラー メッセージが「ページが見つかりません」の場合、Google はそのステータス コードを 404 (not found) と解釈します。
出典:Google による robots.txt の指定の解釈 | Google 検索セントラル | ドキュメント | Google for Developers
以下のようなポイントがあります。
- 503 (service unavailable) エラーの場合、再試行が頻繁に行われる
本記事で確認しているWebページ (前述のページBとC) のドメインでは、この503エラーになっています。ただWebサイト側の設計意図としては、クローラのアクセス再試行を頻繁に行ってほしいというよりは、”Service Unavailable” を示したいだけのような気がしますが。 - robots.txt に 30 日以上アクセスできない場合、robots.txt の最後のキャッシュ コピーが使用される
- 500番台エラーであっても、ページ内のエラーメッセージに基づくGoogleの解釈によって404 (not found) として扱う場合がある (400番台エラーでは、Google はクロールの制限はないものとみなす (=クロールを許可) )
サブドメインの分離
上記の画面が表示されるサブドメイン (メール問い合わせフォームがあるドメイン、前述のページB、C) は、三井住友カードのメインのWebサイトがあるドメイン (www.smbc-card.com、前述のページA) とは別のものです。
- ページA: www.smbc-card.com
- ページB、C: XXX.smbc-card.com
つまり、サブドメインが分離されています (FQDNが別という意味で、別のWebサイト)。
おそらく、XXX.smbc-card.comはサポートや問合せ用のWebサービスを提供するためのサブドメインかと思います。
サブドメイン単位でポリシーの異なる robots.txt の設定になっているということです。
なお、XXX.smbc-card.comでは、コンテンツが存在しないと思われる適当なURLを入力しても、上記と同じ画面および応答ステータスコード (503) となります。
参考までに、三井住友カードのメインのWebサイトがあるドメイン (www.smbc-card.com、前述のページA) の方の robots.txt にはアクセスできるので、そのリンクを載せておきます。
ページA
続いて、各ページのソースから確認できる設定です。
ページAから順に確認していきます。
ページAはメール問い合わせとは直接関係の無い別のキーワードで検索するとヒットします。
このページ自体は、クローラに対する制限が無く、検索エンジンに登録もされています。
ページBへのリンク
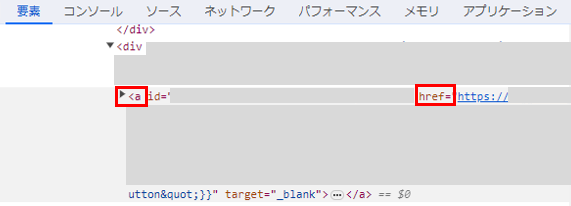
ページAには、ページBへのリンクがあります。
これは通常の<a>タグ内のhref=属性によるリンクであり、rel="nofollow" 属性も設定されていません。
つまり、このリンク自体には、特にクローラの動作を制限したい意図は無さそうです。
ページB
続いて、ページBです。
ページBはメール問い合わせとは別のページで、検索エンジンではヒットしません。
このページは、前述のとおりrobots.txtへのアクセスがHTTPの500番台エラーとなるサブドメイン内にあるので、クローラによるアクセスが許可されておらず、通常の検索エンジンには登録されないためだと考えられます。
ページCへのリンク
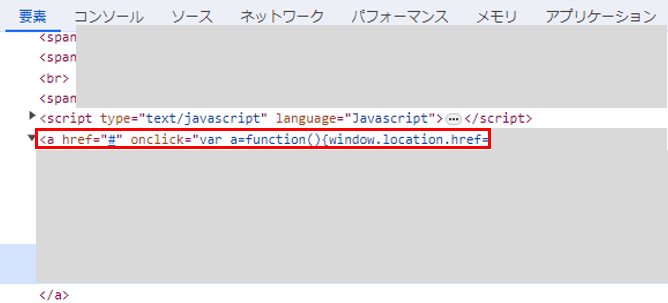
ページBには、ページCへのリンクがあります。
これは通常の<a>タグ内のhref=属性によるリンクではなく、onclick属性のwindow.location.href=(遷移先URL)(JavaScript) によるリンクです。
わざわざこのような形式のリンクにしている理由は、おそらくクローリングを回避するためと推察されます。普通のテキストを記述する要素のリンクで、このように実装する他の理由も思いつかないので。
実際、Googleのドキュメントには以下のように、href=属性が無いリンクはクロールされない旨の記載があります。
通常、リンクが href 属性を持つ <a> HTML 要素(アンカー要素とも呼ばれます)である場合のみ、Google はリンクをクロールできます。その他のフォーマットのリンクのほとんどは解析されず、Google クローラーにより抽出されません。href 属性のない <a> 要素や、スクリプト イベントによりリンクとして機能するタグから URL を信頼できる形で抽出することはできません。
出典:Google の SEO リンクに関するベスト プラクティス | Google 検索セントラル | ドキュメント | Google for Developers
(以下は自分用の覚え書きです)
ページC
続いて、ページCです。
ページCはメール問い合わせフォームが設置されたページで、検索エンジンではヒットしません。
ヒットしない理由はページBと同じです。
さらに、ページ内には<meta content="noindex" name="robots" />が設定されており、ページ単体としても検索エンジンに登録されないようにする意図が読み取れます。
つまり色々な仕組みがある
このように、検索エンジンに登録されないために、色々な考慮がされているであろう点が読み取れます。
もちろん他にも様々な手法があるはずなので、これはほんの一例です。
関連情報
robots.txtでは、Allow、Disallowが基本
本記事では、HTTPの応答ステータスコードによるrobots.txtの扱い方を確認しましたが、通常は、robots.txt内にAllow、Disallowの構文でクローラの許可、拒否を設定することが多いかと思います。
robots.txt等を無視する検索エンジンはあるか
robots.txt等の作法を無視するような検索エンジンがあれば、今回のメール問い合わせフォームが設置されたページもヒットする可能性はあります。
少し探してみたのですが、そのような検索エンジンはさっと見つかりませんでした。
また別の機会があれば探してみたいと思います。
検索結果からの削除ツール
Google の Search Console には、所有しているサイトのページを Google 検索結果から一時的にブロックする機能があります。
Twitter、Google以外の検索エンジンを締め出しへ?
見つけたのでついでに記載しておきます。
まとめ
本記事では、三井住友カードのサポートサービスにおけるフローの現状や、また技術的なSEOの観点から、メール問い合わせページを例に、特定のページ (というか今回はサイト) を検索エンジンに登録させないために、クローラによる探索を許可しないよう設定する方法を確認してみました。



かんたんポイ活

