GPT-3のトークン数制限(text-davinci-003: This model’s maximum context length is 4097 tokens)
当サイトには広告を含みます。広告でなく単なる紹介等の場合もあります。
当サイトでは、広告掲載ポリシーに沿って広告を掲載しています。
※広告でなく、単に商品やサービスを自主的に紹介しているだけという場合もあります。
その中でも "オススメ" として紹介している商品やサービスは、個人的にそう思えたものだけです。
共感、興味をもっていただけるものがあればご利用ください。


API経由でGPT-3を利用していると、”This model’s maximum context length is 4097 tokens,…”というエラーが返ってきました。
本記事では、このエラーについてまとめておきます。
本記事の目的
- GPT-3のAPIを使用する際のトークン数制限について理解する。
エラー概要
Googleスプレッドシートにて、GAS経由でGPT-3のAPIにリクエストした際、以下のエラーが返ってきました。
This model's maximum context length is 4097 tokens, however you requested 4126 tokens (126 in your prompt; 4000 for the completion). Please reduce your prompt; or completion length."
Googleスプレッドシート固有のエラーではなく、GPT-3によるエラーです。
対処方法まで記載されていますが、とりあえず制限を超過した的なメッセージです。
GPT-3のtext-davinci-003モデルは4097トークンまで
GPT-3では、1回のAPIやり取りにおける問合せの内容(prompt)と応答の内容(completion)の合計トークン数に制限があります。
制限値はモデルによって異なります。本記事の作成時点で、GPT-3において通常使用されているtext-davinci-003のエラーメッセージ上は4097のようです。違う数値で説明されていることもあるので、補足事項として後述します。
トークン数は、文字数や単語数とは異なります。トークンは、文章がtokenizerという機能により分解されたものです。
対処は、promptを短くするか、max_tokensを小さくすること
エラーメッセージにPlease reduce your prompt; or completion length.と書かれていますので、それが対処です。
APIへのリクエスト送信時、promptとmax_tokensを指定しているはずですので、これを調整して制限内に収まるようにすればエラーが解消されます。
-
prompt
GPT-3に問い合わせる文章を指定するパラメタです。APIに送信後、トークンに分解されます。この文章を短くすれば、promptのトークン数が小さくなります。 -
max_tokens
APIからの応答のトークン数の最大値を指定するパラメタです。この値を小さくすれば、そのトークン数に応じて応答の長さ(completion length)が小さくなります。逆に、応答の長さ(completion length)が大きいということは、トークン数が多いということになります。
GPT-3により生成される応答のトークン数はmax_tokensの範囲内となります。
もう少し詳しい内容を、後述していきます。
補足事項
トークンとは
トークン数は、文字数や単語数とは異なります。トークンは文章がtokenizerにより分解されたものです。
詳細は、Tokensから辿れます。
For example, the word “hamburger” gets broken up into the tokens “ham”, “bur” and “ger”, while a short and common word like “pear” is a single token.
と例示されています。”hamburger”の”ham”、”bur”、”ger”は語源が見当たらなかったのですが、どちらかと言うと音節のような気もしますが…tokenizerの仕様までは理解できていないので、そのように扱われるということでしょう。
大まかな目安として、英語の文章で1トークンは約4文字、もしくは0.75単語になると記載があります。
Tokenizerの動作確認ツール
Tokenizerにて、実際に文章がどのようにtokenizeされるかを確認することができます。
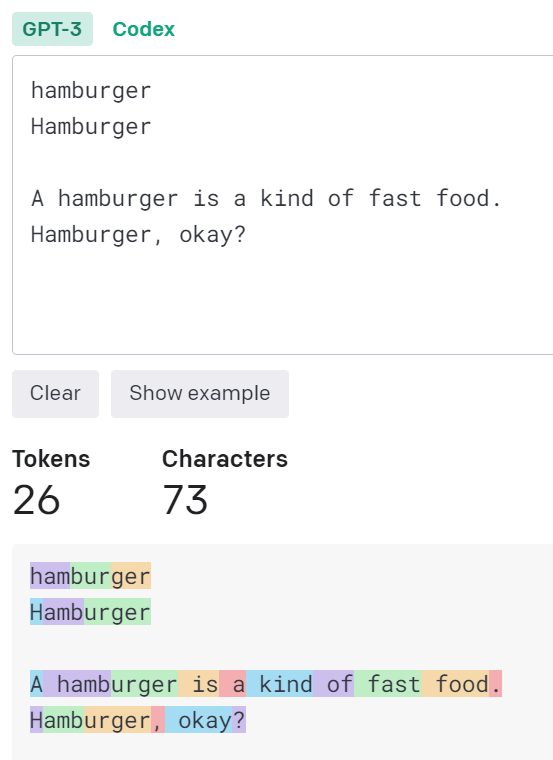
確かに、”hamburger”が”ham”、”bur”、”ger”というtokenに分解されています。
しかし最初の1文字を大文字にすると、”H”、”amb”、”urger”です。
また、文章にすると、” hamb”、”urger”です。
“hamburger”の分解の仕方がまちまちです。不思議ですね。
tokenizerの仕組みを深く理解するのは難しいので、このように扱われるものだと知っておく程度にしておきます。
扱えるトークン数の上限(context length)
GPT-3のモデルごとに扱えるトークン数(context length)の上限は異なります。
以下の2つの合計が、その上限内に収まっている必要性があります。
- 問合せの内容(prompt)のトークン数
- 応答の内容(completion)の最大トークン数(
max_tokens)
これらの、APIへのリクエストにおいて指定するpromptやmax_tokensについては、APIリファレンスのCreate completionに説明があります。
制限値は4097か4096か4000か
-
エラーメッセージでは、前述の通り4097でした(“This model’s maximum context length is 4097 tokens”)。これは、問合せ(prompt)と応答(completion)の両方のトークン数の合計に対する制限です。
-
GPT-3の説明には、
MAX REQUESTが”4,000 tokens”と記載されています。REQUESTなので問合せの方だけを指しているのかもしれません。詳細は未確認ですが、前述の4097を考慮すると、promptで4000を消費してしまうと、completionが97以内になるようにmax_tokensを指定しないといけないような気がします。 -
API REFERENCEには、”except for the newest models, which support 4096″と記載されています。4097より1小さいですね。内部的にendoftext的なものが1トークンの差異になっているのかも知れませんが、詳細は不明です。
細かいところは分かりませんが、そもそもtokenizerの仕組みを理解できないので、上記をざっくり把握できていれば、実用上は問題なさそうです。
なお、”context length”と表現されている場合、それは問合せ(prompt)と応答(completion)の両方のトークン数の合計を指しているようです。
まとめ
API経由でGPT-3を使った際の”This model’s maximum context length is 4097 tokens”のエラーについてまとめてみました。
今後も色々試していきたいと思います。




